Introduccion a x86 ASM - Registros
Assembler no es un lenguaje. Es una familia de lenguajes dependientes de la arquitectura de los procesadores.
Esta familia de lenguajes es fundamental en ingeniería inversa.
Me fascina el concepto de ingeniería inversa aunque aún soy un lego casi total en la materia: esta guía también me sirve a mi. Por otra parte, demasiados desarrolladores no saben lo que es la ingeniería inversa y demasiados desarrolladores piensan en Assembler como si fuera un lenguaje de programación obsoleto.
Esta serie de entradas, inspirada en esta otra Guía de la Universidad de Virginia pretende ser una guía introductoria al lenguaje assembler usado en los procesadores Intel x86. Como guía introductoria cubre solamente una pequeña porción (pero útil) de las directivas e instrucciones disponibles.
Así como existen un lenguaje ensamblador para cada arquitectura, existen varios lenguajes para generar código máquina para procesadores x86.
Esta guía utiliza el assembler de Microsoft Macro Assembler (MASM), que usa la sintaxis estándar de Intel.
El conjunto de instrucciones completo para los x86 es extenso y complejo (sus manuales respecto al conjunto de instrucciones tiene más de 2900 páginas) y por ello no lo cubrimos completo en esta guía. Por ejemplo, existe un subconjunto de 16-bits del conjunto de instrucciones x86. Usar el modelo de programación de este subconjunto puede ser bastante complejo. Tiene un modelo de memoria segmentada, más restricciones en el uso de registros, etc. En esta guía vamos a enfocarnos en los aspectos más modernos de la programación x86 y no deternos más de lo necesario en aspectos específicos del conjunto de instrucciones. Comencemos.
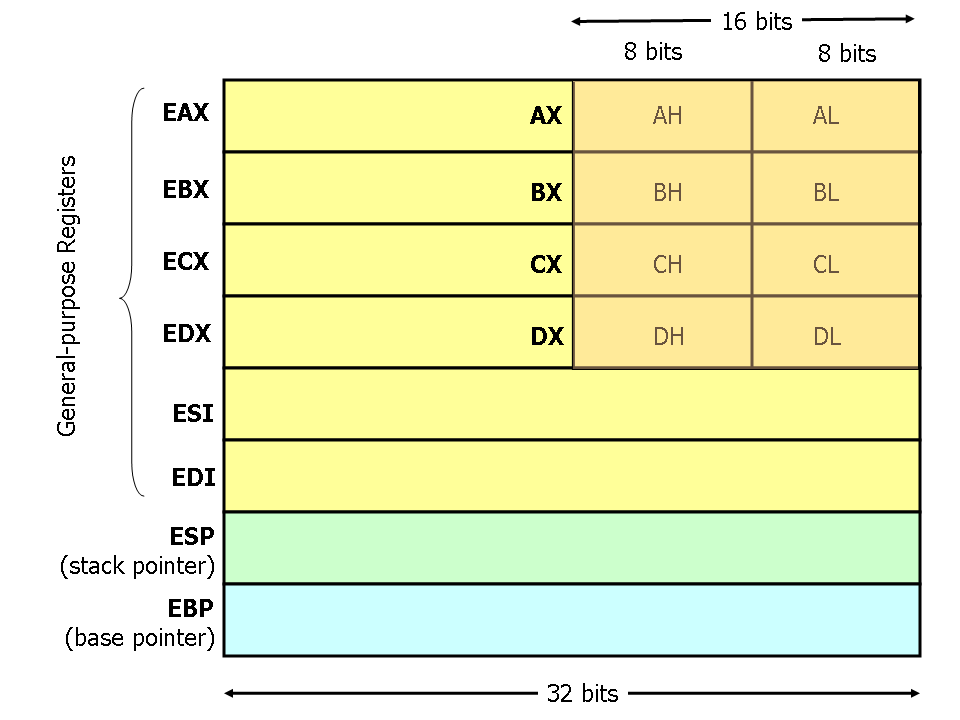 ¿Te estás preguntando porque el nombre de todos estos registros comienzan con "E"?
¿Te estás preguntando porque el nombre de todos estos registros comienzan con "E"?
Es porque el conjunto original de registros de Intel era de 16-bits y los registros se llamaban AX, BX, etc. Cuando se consideró que 16-bits no eran suficientes y se comenzó a utilizar 32-bits, se agregó la E de Extended (o Enhanced) como prefijo a los registros. En los procesadores actuales 64-bits, los registros se llaman RAX, RBX, etc. donde la R significa Registro, el sentido de esto excede el alcance de esta guía, pero GIYF.
Los nombres de los registros son mayormente históricos. Por ej. EAX solía ser llamado el "acumulador" desde que era utilizado por ciertas operaciones aritméticas y ECX era conocido como el "contador" desde que era utilizado para mantener almacenado el indice de un loop. Aunque la mayoría de los registros han perdido sus propósitos generales en los conjuntos de instrucciones modernas, por convención, 2 de ellos aún se reservan para propósitos específicos: ESP (Stack pointer) y EBP (Base pointer).
Otro aspecto importante que puede verse en la figura presentada es la utilización de subsecciones para los registros EAX, EBX, ECX, y EDX. Por ejemplo, los 2 bytes menos significativos de EAX pueden ser tratados como registros de 16-bits llamados AX. El byte menos significativo de AX puede ser usado como un registro de 8-bits llamado AL y el más signicativo como un registro de 8-bits llamado AH. En caso de que lo dudes, L y H son las iniciales de "Low" y "High". Todos estos nombres (EAX, AX, AH y AL) refieren al mismo registro físico. Esto quiere decir que cuando, por ejemplo, una cantidad de 2-bytes se guarda en DX, la actualización del valor afecta a DH, DL y EDX. Esos sub-registros son mantenidos principalmente por razones de compatibilidad hacia atrás pero a veces puede ser conveniente usarlos cuando trabajamos con datos que tienen menos de 32-bits (como un caracter ASCII, de 1 byte). Los nombres de los registros no son sensibles a mayúsculas y minúculas así que los nombres EAX y eax refieren al mismo registro.
En la próxima entrada hablaremos de la memoria y los modos de direccionamiento.
Esta familia de lenguajes es fundamental en ingeniería inversa.
Me fascina el concepto de ingeniería inversa aunque aún soy un lego casi total en la materia: esta guía también me sirve a mi. Por otra parte, demasiados desarrolladores no saben lo que es la ingeniería inversa y demasiados desarrolladores piensan en Assembler como si fuera un lenguaje de programación obsoleto.
Esta serie de entradas, inspirada en esta otra Guía de la Universidad de Virginia pretende ser una guía introductoria al lenguaje assembler usado en los procesadores Intel x86. Como guía introductoria cubre solamente una pequeña porción (pero útil) de las directivas e instrucciones disponibles.
Así como existen un lenguaje ensamblador para cada arquitectura, existen varios lenguajes para generar código máquina para procesadores x86.
Esta guía utiliza el assembler de Microsoft Macro Assembler (MASM), que usa la sintaxis estándar de Intel.
El conjunto de instrucciones completo para los x86 es extenso y complejo (sus manuales respecto al conjunto de instrucciones tiene más de 2900 páginas) y por ello no lo cubrimos completo en esta guía. Por ejemplo, existe un subconjunto de 16-bits del conjunto de instrucciones x86. Usar el modelo de programación de este subconjunto puede ser bastante complejo. Tiene un modelo de memoria segmentada, más restricciones en el uso de registros, etc. En esta guía vamos a enfocarnos en los aspectos más modernos de la programación x86 y no deternos más de lo necesario en aspectos específicos del conjunto de instrucciones. Comencemos.
Registros
Los procesadores x86 modernos (desde 386 en adelante) tiene 8 registros de 32 bits de propósito general, como se muestra en la sgte. figura:
Es porque el conjunto original de registros de Intel era de 16-bits y los registros se llamaban AX, BX, etc. Cuando se consideró que 16-bits no eran suficientes y se comenzó a utilizar 32-bits, se agregó la E de Extended (o Enhanced) como prefijo a los registros. En los procesadores actuales 64-bits, los registros se llaman RAX, RBX, etc. donde la R significa Registro, el sentido de esto excede el alcance de esta guía, pero GIYF.
Los nombres de los registros son mayormente históricos. Por ej. EAX solía ser llamado el "acumulador" desde que era utilizado por ciertas operaciones aritméticas y ECX era conocido como el "contador" desde que era utilizado para mantener almacenado el indice de un loop. Aunque la mayoría de los registros han perdido sus propósitos generales en los conjuntos de instrucciones modernas, por convención, 2 de ellos aún se reservan para propósitos específicos: ESP (Stack pointer) y EBP (Base pointer).
Otro aspecto importante que puede verse en la figura presentada es la utilización de subsecciones para los registros EAX, EBX, ECX, y EDX. Por ejemplo, los 2 bytes menos significativos de EAX pueden ser tratados como registros de 16-bits llamados AX. El byte menos significativo de AX puede ser usado como un registro de 8-bits llamado AL y el más signicativo como un registro de 8-bits llamado AH. En caso de que lo dudes, L y H son las iniciales de "Low" y "High". Todos estos nombres (EAX, AX, AH y AL) refieren al mismo registro físico. Esto quiere decir que cuando, por ejemplo, una cantidad de 2-bytes se guarda en DX, la actualización del valor afecta a DH, DL y EDX. Esos sub-registros son mantenidos principalmente por razones de compatibilidad hacia atrás pero a veces puede ser conveniente usarlos cuando trabajamos con datos que tienen menos de 32-bits (como un caracter ASCII, de 1 byte). Los nombres de los registros no son sensibles a mayúsculas y minúculas así que los nombres EAX y eax refieren al mismo registro.
En la próxima entrada hablaremos de la memoria y los modos de direccionamiento.
Comentarios
Publicar un comentario